智算中心网络架构
学习资料:
《百度智能云 智算中心网络架构白皮书》
NVIDIA MLNX_OFED
NVIDIA Firmware Tools (MFT)
RedHat 配置 InfiniBand 和 RDMA 网络
NVIDIA MFT文档
RedHat 安装配置OpenSM
大模型训练集群的网络要求
大模型训练中的大规模参数对算力和显存都有较高的要求,为了缩短训练时间,需要通过分布式训练的方式,将模型参数和计算任务分配到多个计算节点上。
分布式训练系统的整体算力并不是简单的随着智算节点的增加而线性增加,而是存在加速比,且加速比小于1。存在加速比的原因是:在分布式训练中,计算节点之间需要频繁的进行通信,包括参数的同步、梯度的同步等,这些通信延迟会降低训练速度。
降低多机多卡间端到端通信时延的关键技术是 RDMA 技术。 RDMA 可以绕过操作系统内核, 让一台主机可以直接访问另外一台主机的内存。
RDMA
RDMA是一种新的直接内存访问技术,RDMA让计算机可以直接存取其他计算机的内存,而不需要经过处理器的处理。RDMA将数据从一个系统快速移动到远程系统的内存中,而不对操作系统造成任何影响。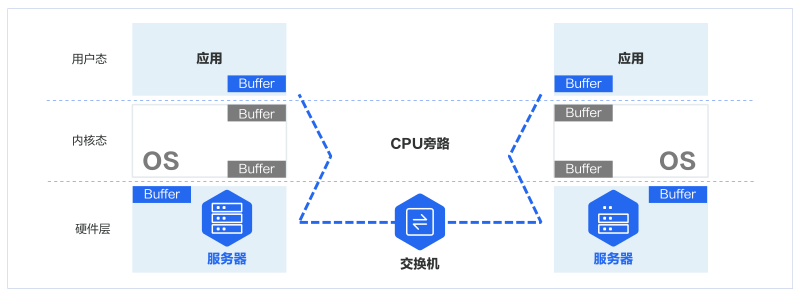
实 现 RDMA 的 方 式 有 InfiniBand、 RoCEv1、 RoCEv2、 i WARP 四 种。 其 中 RoCEv1 技 术 当 前 已 经 被 淘 汰,
iWARP 使用较少。 当前 RDMA 技术主要采用的方案为 InfiniBand 和 RoCEv2 两种。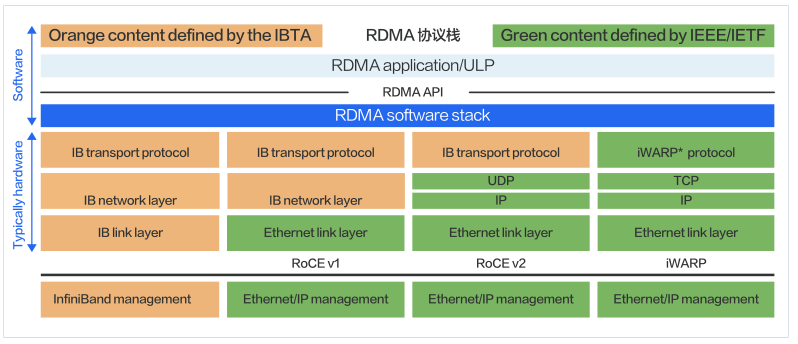
InfiniBand
InfiniBand(直译为“无限带宽”技术,缩写为IB)是一个用于高性能计算的计算机网络通信标准,它具有极高的吞吐量和极低的延迟,用于计算机与计算机之间的数据互连。InfiniBand也用作服务器与存储系统之间的直接或交换互连,以及存储系统之间的互连。
InfiniBand网络的关键组成包括Subnet Manager( SM)、 InfiniBand 网卡、 InfiniBand交换机和InfiniBand连接线缆。
IB端口速率

IB(InfiniBand)端口速率对应不同的网卡、连接件和交换机。不同的IB网卡、线缆和交换机支持不同的数据传输速率
IB网卡
IB网卡通常被称为HCA(Host Channel Adapter)。HCA是InfiniBand网络中的主机通道适配器,它连接主机系统(如服务器)和InfiniBand网络。HCA负责处理InfiniBand网络的数据传输,并提供高性能、低延迟的网络通信。HCA通常集成在服务器的主板或作为独立适配器安装。
IB Switch交换机
IB Switch(InfiniBand Switch)是InfiniBand网络中的核心设备,用于连接多个HCA(Host Channel Adapter)和设备,实现数据的高效传输。IB Switch具有高性能、低延迟和高度可扩展性等特点。
连接件
InfiniBand 网络需要专用的线缆和光模块做交换机间的互联以及交换机和网卡的互联。
例如NDR交换机在Spine-Leaf层之间布线方式为双端使用800Gb光模块,Leaf到GPU服务器之间,Leaf交换机侧使用800Gb光模块,GPU服务器侧连接两个400Gb光模块。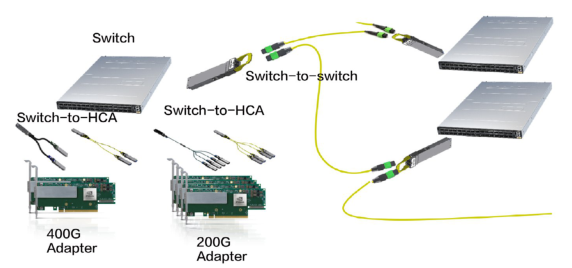
Subnet Manager
InfiniBand 交换机上不运行任何路由协议。 整个网络的转发表是由集中式的子网管理器( Subnet Manager, 简称 SM)
进行计算并统一下发的。SM 有 OpenSM( 开源) 和 UFM( 收费) 两种模式。
- 部署:SM 通常部署在接入 InfiniBand 子网的一台服务器上, 可以把子网管理器理解为 InfiniBand 网络的控制器。一个子网内同时只能有一个 SM 工作, 如有多个设备配置成为 SM, 则只有一个 SM 能成为主 SM。
- 控制机制:SM 可以控制整个子网内所有的 InfiniBand 交换机和 InfiniBand 网卡, 控制信令也通过InfiniBand 网络带内下发和上传( 统称 MAD, Management Datagram) 。 所有 InfiniBand 网卡端口和交换芯片都有一个子网内唯一的身份标识 LID( Local ID) , 由 SM 赋予。 SM 会计算每个交换芯片的路由表并下发。 SM 控制 InfiniBand 网卡, 并不需要 InfiniBand 网卡所在服务器的协助。
相关命令
OpenSM 是 InfiniBand 网络中的一个开源子网管理器(Subnet Manager),用于管理和配置 InfiniBand 子网。
需要使用 rdma-core、libibverbs-utils、infiniband-diags包支持,
- 配置IPoIB
1
2
3
4
5
6
7
8
9
10
11MST工具查看网卡与以太网卡标识
mst status -v
------------
DEVICE_TYPE MST PCI RDMA NET NUMA
ConnectX6(rev:0) /dev/mst/mt4123_pciconf0 98:00.0 mlx5_4 net-ib0 1
centos中配置/etc/sysconfig/network-scripts/ifcfg-<interface_name>
配置完成后重启网络服务或者启用接口
systemctl restart network
或者
ifup ib0 - ibstat查看IB网卡状态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15CA 'mlx5_0' # 网卡名称
CA type: MT41170 # 网卡类型
Number of ports: 1 # 网卡端口数量
Firmware version: 16.28.1000 # 网卡固件版本
Hardware version: a0 # 网卡硬件版本
Node GUID: 0x00155d0300d1a9e0 # 网卡GUID
System image GUID: 0x00155d0300d1a9e0 # 网卡系统GUID
Port 1:
State: Active # 网卡端口状态
Physical state: LinkUp # 网卡物理状态
Rate: 100 # 网卡速率
Base lid: 0 # 网卡基础LID
SM lid: 0
Port GUID: 0x00155d0300d1a9e1
Link layer: InfiniBand # 网卡链路层协议 - ibswitches获取当前子网的所有交换机的信息
1
2
3
4
5
6
7
8
9
10
11~]# ibswitches
Switch : 0x946dae030016474e ports 41 "Quantum Mellanox Technologies" base port 0 lid 25 lmc 0
Switch : 0x946dae030016488e ports 41 "Quantum Mellanox Technologies" base port 0 lid 8 lmc 0
Switch : 0x946dae0300164ace ports 41 "Quantum Mellanox Technologies" base port 0 lid 39 lmc 0
Switch : 0x946dae030016476e ports 41 "Quantum Mellanox Technologies" base port 0 lid 31 lmc 0
Switch : 0x946dae03000ca39a ports 41 "Quantum Mellanox Technologies" base port 0 lid 35 lmc 0
Switch : 0x946dae0300095e9a ports 41 "Quantum Mellanox Technologies" base port 0 lid 33 lmc 0
Switch : 0x946dae0300095f1a ports 41 "Quantum Mellanox Technologies" base port 0 lid 22 lmc 0
Switch : 0x946dae030016482e ports 41 "Quantum Mellanox Technologies" base port 0 lid 23 lmc 0
Switch : 0x946dae0300095c9a ports 41 "Quantum Mellanox Technologies" base port 0 lid 32 lmc 0
Switch : 0x946dae0300095eda ports 41 "Quantum Mellanox Technologies" base port 0 lid 45 lmc 0 - ofed_info检测ofed驱动版本
1
ofed_info -s
- iblinkinfo 查看IB网卡连接信息
1
2
3
4
5
6
7Switch: 0x946dae030016494e Quantum Mellanox Technologies:
#lid port state rate link
26 1[ ] ==( 4X 53.125 Gbps Active/ LinkUp)==> 40 1[ ] "Quantum Mellanox Technologies" ( )
26 2[ ] ==( 4X 53.125 Gbps Active/ LinkUp)==> 40 2[ ] "Quantum Mellanox Technologies" ( )
26 3[ ] ==( 4X 53.125 Gbps Active/ LinkUp)==> 24 1[ ] "Quantum Mellanox Technologies" ( )
26 4[ ] ==( 4X 53.125 Gbps Active/ LinkUp)==> 24 2[ ] "Quantum Mellanox Technologies" ( ) - sminfo获取当前节点的子网管理器的信息
1
2~]# sminfo
sminfo: sm lid 1 sm guid 0x946dae0300146a70, activity count 117783369 priority 0 state 3 SMINFO_MASTER - ibswitches获取当前子网的所有交换机的信息
- ibhosts取当前子网的所有HCA的信息
- ibnodes获取当前子网的所有交换机和HCA的信息
- ibnetdiscover 获取 当前子网的所有交换机和HCA的信息
1
2
3
4
5
6vendid=0x2c9 # 网卡厂商ID
devid=0xcf09 # 网卡设备ID
sysimgguid=0x946dae03000c9c9a # 网卡系统GUID
caguid=0x946dae03000c9ca2 # 网卡GUID
Ca 1 "H-946dae03000c9ca2" # "Mellanox Technologies Aggregation Node"
[1](946dae03000c9ca2) "S-946dae03000c9c9a"[41] # lid 305 lmc 0 "Quantum Mellanox Technologies" lid 34 4xHDR
物理网络架构
在智算场景中,当前比较好的实践是独立建一张高性能网络来承载智算业务, 满足大带宽, 低时延, 无损的需求。
- 大带宽设计
智算服务器可以满配 8 张 GPU 卡, 并预留 8 个 PCIe 网卡插槽。 在多机组建 GPU 集群时, 两个 GPU 跨机互通的突发带宽有可能会大于 50Gbps。 因此, 一般会给每个 GPU 关联一个至少 100Gbps 的网络端口。 在这种场景下可以配置 4张 2100Gbps 的网卡, 也可以配置 8 张 1100Gbps 的网卡, 当然也可以配置 8 张单端口 200/400Gbps 的网卡。
- 无阻塞设计
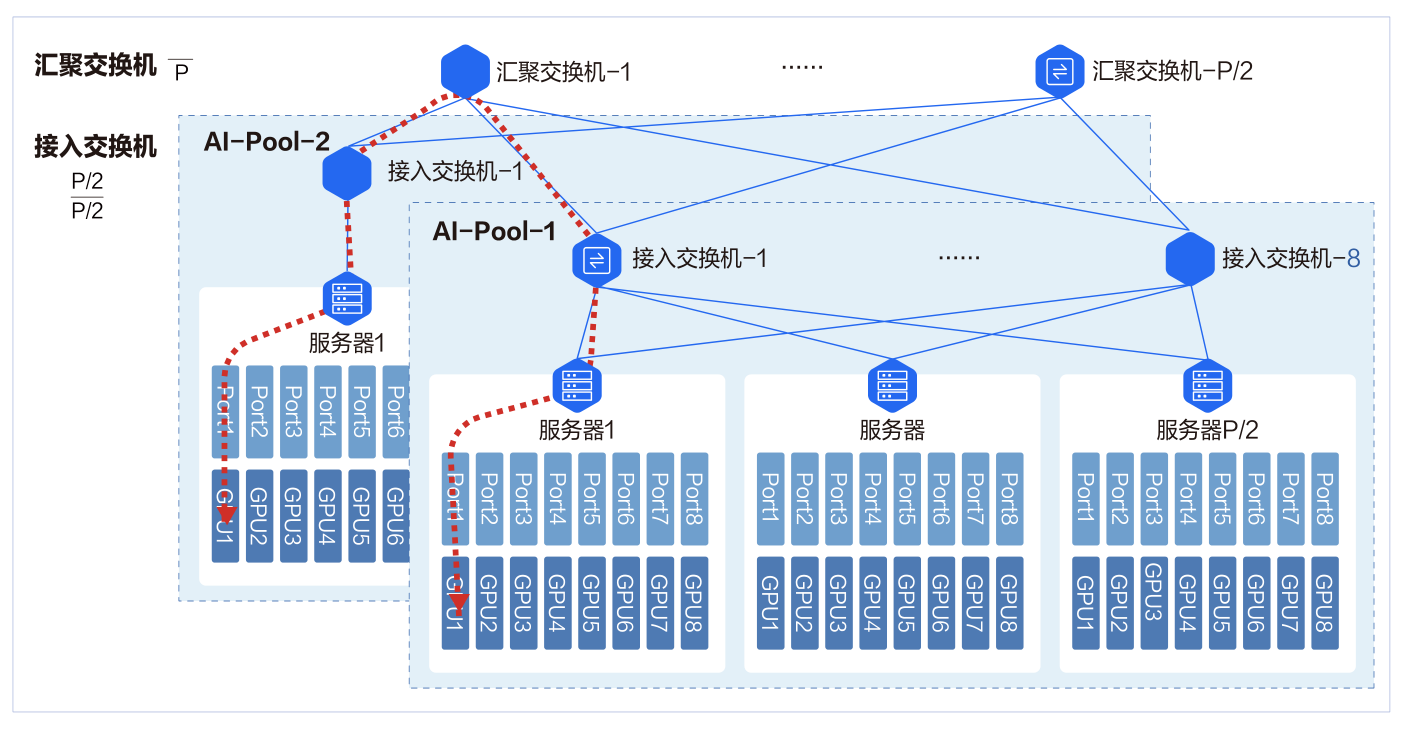
无阻塞网络设计的关键是采用 Fat-Tree( 胖树) 网络架构。 交换机下联和上联带宽采用 1: 1 无收敛设计, 即如果下联有64 个 100Gbps 的端口, 那么上联也有 64 个 100Gbps 的端口。 - 低时延设计 AI-Pool
8 个接入交换机为一组, 构成一个 AI-Pool。 以两层交换机组网架构为例, 这种网络架构能做到同 AI-Pool 的不同智算节点的 GPU 互访仅需一跳。在 AI-Pool 网络架构中, 不同智算节点间相同编号的网口需要连接到同一台交换机。 如智算节点 1 的 1 号 RDMA 网口,智算节点 2 的 1 号 RDMA 网口直到智算节点 P/2 的 1 号 RDMA 网口都连到 1 号交换机。
在智算节点内部, 上层通信库基于机内网络拓扑进行网络匹配, 让相同编号的 GPU 卡和相同编号的网口关联。 这样相同GPU 编号的两台智算节点间仅一跳就可互通。
不同GPU编号的智算节点间, 借助NCCL通信库中的Rail Local技术, 可以充分利用主机内GPU间的NVSwitch的带宽,将多机间的跨卡号互通转换为跨机间的同GPU卡号的互通。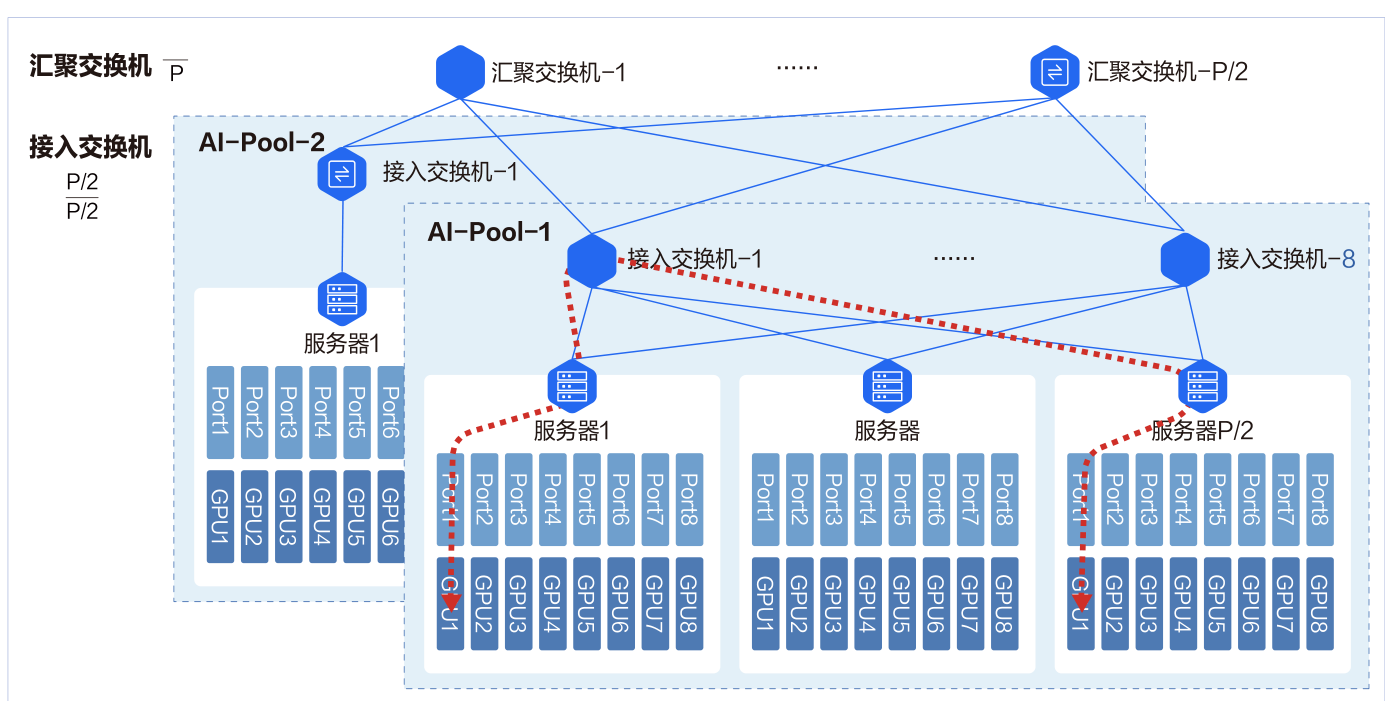
智算网络可容纳的GPU卡的规模
网络可承载的 GPU 卡的规模和所采用交换机的端口密度、 网络架构相关。 网络的层次多, 承载的 GPU 卡的规模会变大,但转发的跳数和时延也会变大, 需要结合实际业务情况进行权衡。
两层胖树架构
8 台接入交换机组成一个智算资源池 AI-Pool。 图中 P 代表单台交换机的端口数。 单台交换机最大可下联和上联的端口为P/2 个, 即单台交换机最多可以下联 P/2 台服务器和 P/2 台交换机。 两层胖树网络可以接入 P*P/2 张 GPU 卡。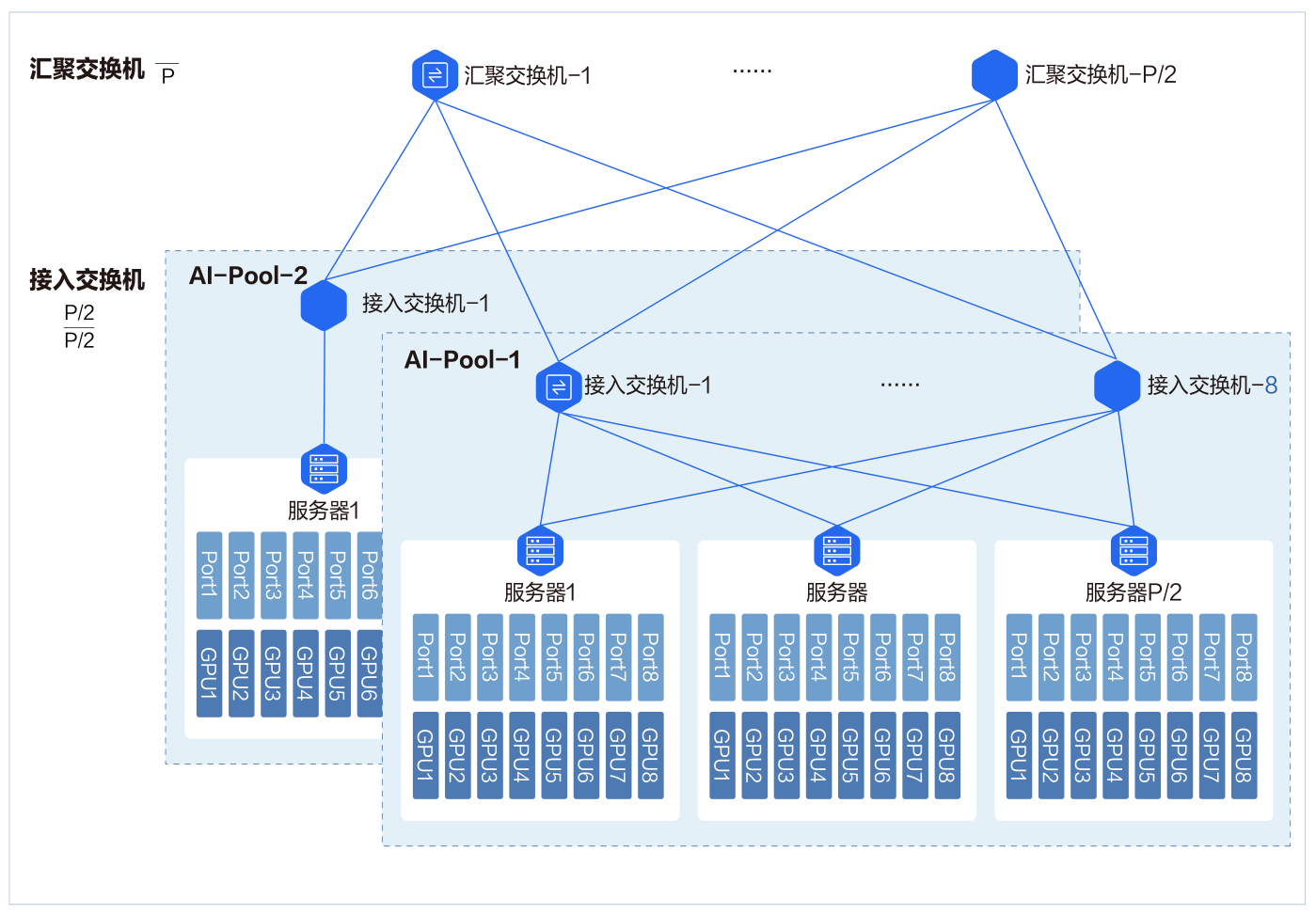
三层胖树架构
三层网络架构中会新增汇聚交换机组和核心交换机组。 每个组里面的最大交换机数量为 P/2。 汇聚交换机组最大数量为 8,核心交换机组的最大数量为 P/2。 三层胖树网络可以接入 P*(P/2)*(P/2)=P*P*P/4 张 GPU 卡。
在三层胖树组网中, InfiniBand 的 40 端口的 200Gbps HDR 交换机能容纳的最多 GPU 数量是 16000。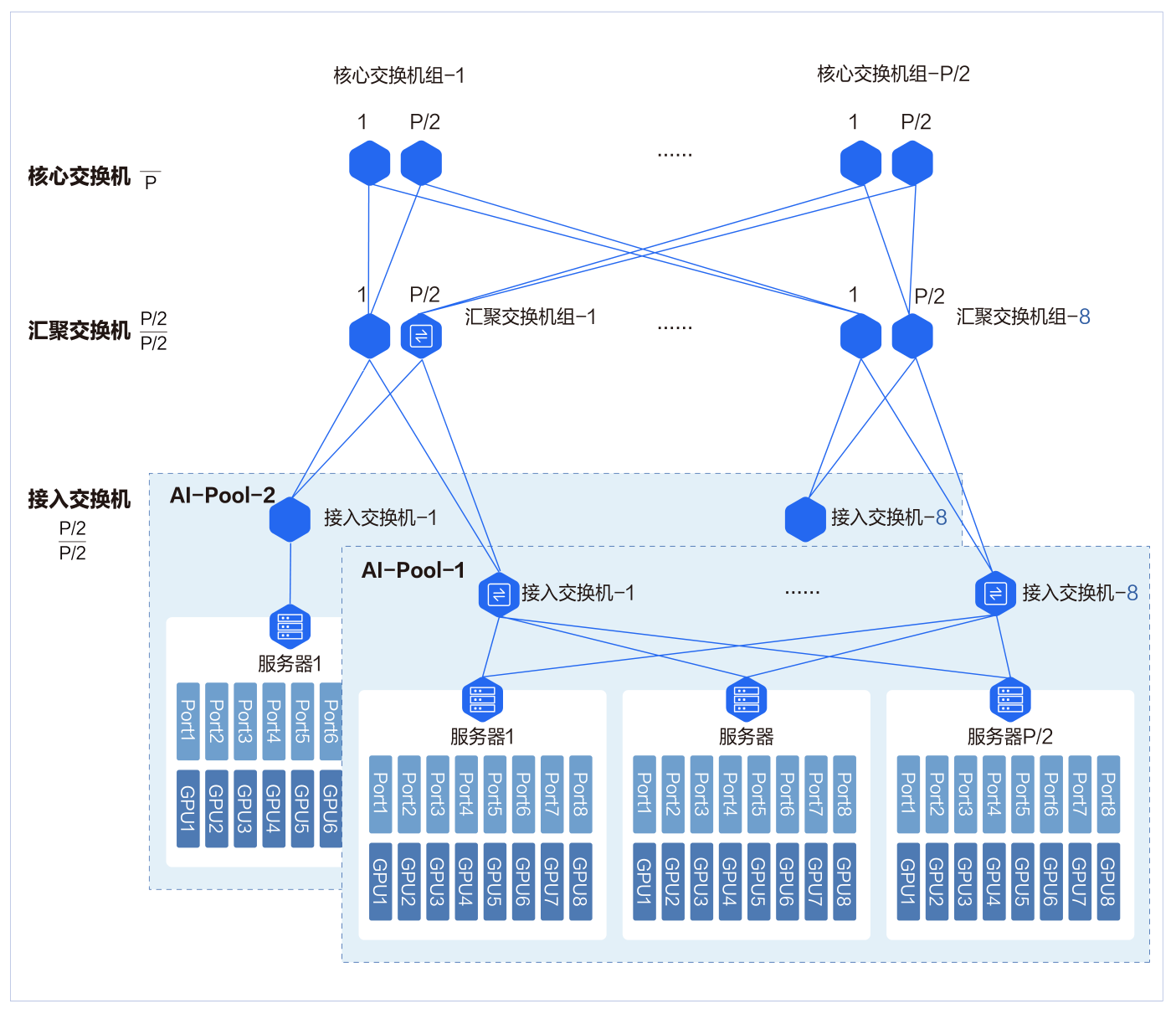
两层与三层胖树对比

