GPUDirect RDMA
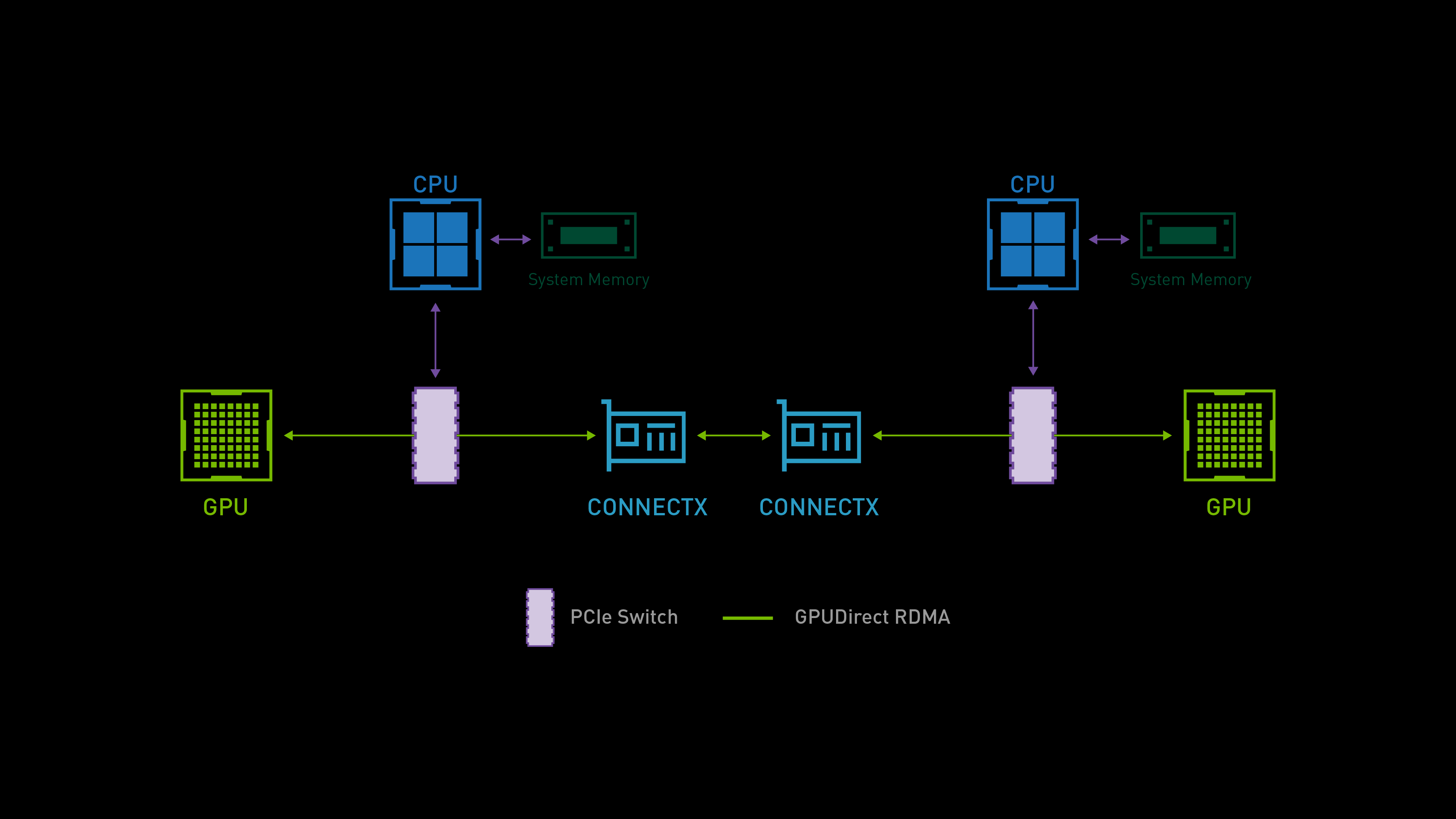
GPUDirect RDMA
GPUDirect RDMA 结合了 GPU 加速计算和 RDMA(Remote Direct Memory Access)技术,实现了在 GPU 和 RDMA 网络设备之间直接进行数据传输和通信的能力。它允许 GPU 直接访问 RDMA 网络设备中的数据,无需通过主机内存或 CPU 的中介。
GPUDirect RDMA 通过绕过主机内存和 CPU,直接在 GPU 和 RDMA 网络设备之间进行数据传输,显著降低传输延迟,加快数据交换速度,并可以减轻 CPU 负载,释放 CPU 的计算能力。另外,GPUDirect RDMA 技术允许 GPU 直接访问 RDMA 网络设备中的数据,避免了数据在主机内存中的复制,提高了数据传输的带宽利用率。
- GPU 内存可以直接暴露给 RDMA 设备:InfiniBand 网卡可以直接读取或写入 GPU 内存,而无需经过 CPU 或主机内存中转。
- GPU 可以间接访问其他节点的内存:虽然 GPU 本身不能直接访问远程内存,但通过 GPUDirect RDMA,InfiniBand 网卡可以直接将数据传输到远程节点的内存中(无论是 CPU 内存还是 GPU 内存)。
- GPU 本身不能直接访问远程内存,但通过 GPUDirect RDMA,InfiniBand 网卡可以直接访问 GPU 内存,从而实现 GPU 与其他节点内存的高效通信。
GPUDirect RDMA使用的前置条件
- GPU支持GPUDirect RDMA技术:Tesla与Quadro GPU 系列产品支持GPUDirect RDMA技术。
- 网卡支持GPUDirect RDMA技术:InfiniBand 网卡支持 GPUDirect RDMA 技术,例如 Mellanox 的 ConnectX 系列产品。
- 操作系统支持:Linux 操作系统需要安装 NVIDIA 和 Mellanox 的驱动程序。
- PCIe 拓扑结构:GPU 和 InfiniBand 网卡需要通过 PCIe 总线连接。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36#通过此命令查看GPUDirect RDMA支持的拓扑结构信息:GPU不在NUMA内,但是优先使用NUMA Affinity对应的node0/1的内存
nvidia-smi topo -m
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 NIC0 NIC1 NIC2 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X PIX PXB PXB SYS SYS SYS SYS NODE NODE PXB 0-31 0 N/A
GPU1 PIX X PXB PXB SYS SYS SYS SYS NODE NODE PXB 0-31 0 N/A
GPU2 PXB PXB X PXB SYS SYS SYS SYS NODE NODE PXB 0-31 0 N/A
GPU3 PXB PXB PXB X SYS SYS SYS SYS NODE NODE PIX 0-31 0 N/A
GPU4 SYS SYS SYS SYS X PIX PXB PXB SYS SYS SYS 32-63 1 N/A
GPU5 SYS SYS SYS SYS PIX X PXB PXB SYS SYS SYS 32-63 1 N/A
GPU6 SYS SYS SYS SYS PXB PXB X PXB SYS SYS SYS 32-63 1 N/A
GPU7 SYS SYS SYS SYS PXB PXB PXB X SYS SYS SYS 32-63 1 N/A
NIC0 NODE NODE NODE NODE SYS SYS SYS SYS X PIX NODE
NIC1 NODE NODE NODE NODE SYS SYS SYS SYS PIX X NODE
NIC2 PXB PXB PXB PIX SYS SYS SYS SYS NODE NODE X
Legend:
# 设备自身
X = Self
# 跨 NUMA 节点的设备之间,通信路径较长,可能涉及 CPU 和高速互联(如 Intel 的 QPI 或 AMD 的 UPI)
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
# PCIe 以及 同一 NUMA 节点内 PCIe 主机桥(PHB)之间的互连,同一 NUMA 节点内的设备之间,通信路径较短,性能优于 SYS
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
# 通过 PCIe 以及 一个 PCIe 主机桥(PHB)
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
# 通过 多个 PCIe 桥,但 不经过 PCIe 主机桥(PHB)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
# 连接最多通过 一个 PCIe 桥,性能最佳,因为通信路径最短
PIX = Connection traversing at most a single PCIe bridge
# 通过 一组绑定的 NVLink,“#”表示绑定的 NVLink 数量
NV# = Connection traversing a bonded set of # NVLinks
NIC Legend:
NIC0: mlx5_0
NIC1: mlx5_1
NIC2: mlx5_2
NUMA:非一致性内存访问,是一种内存访问技术,允许不同处理器核心或处理器模块直接访问物理内存的不同部分。在多核处理器或多处理器系统中,NUMA架构旨在减少跨处理器核心的内存访问延迟,
1 | #查看CPU和NUMA的对应关系 |
开启GPUDirect RDMA
- Mellanox OFED( InfiniBand驱动和软件栈)
- 安装GPU驱动程序、cuda工具包
- 内核模块:nvidia_peermem(较新的驱动)、nv_peer_memory (较旧的驱动)
注意:要先安装 Mellanox OFED,再安装驱动和cuda工具包,最后加载模块。确保使用 MLNX_OFED 提供的 RDMA API 进行编译。
1 | # 加载模块 |